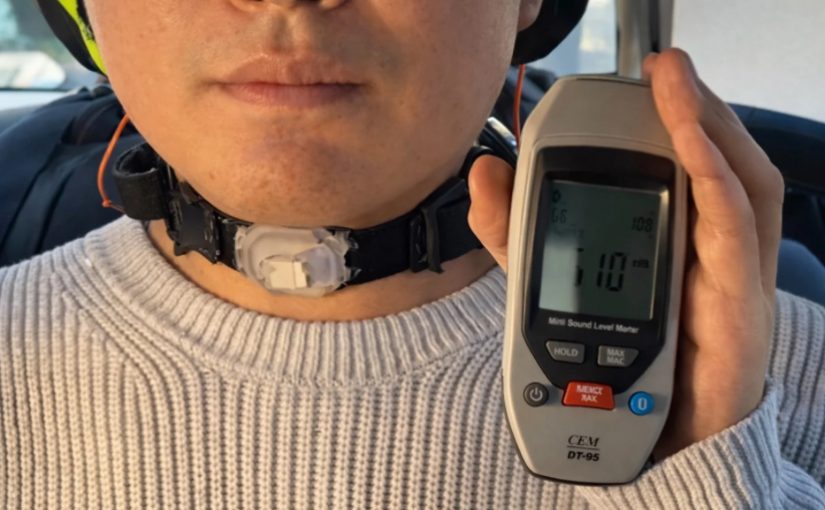
[星島綜合報道]南韓浦項科技大學(POSTECH)研究團隊開發一款柔軟矽膠頸帶,結合微型鏡頭、動作感應器及人工智能模型,可讀取佩戴者無聲讀字時頸部皮膚與肌肉的細微變化,再將內容轉化為語音,並以接近用戶本人的聲線播放。
這款裝置針對「無聲語音介面」而設計。研究指出,人類說話時即使沒有發聲,口腔、喉嚨及頸部皮膚仍會出現可預測的變形。過往相關技術多依賴肌電圖或腦電圖,但通常需要笨重設備及貼附式電極,舒適度及實際應用都有限。
POSTECH 的方案改用軟身矽膠頸帶,內置「多軸應變映射感測器」,不但偵測皮膚變形幅度,亦能辨識移動方向。頸帶上的參考標記配合微型鏡頭,可即時量度頸部變化;演算法則會修正每次佩戴位置的細微差異,令系統讀取更穩定。
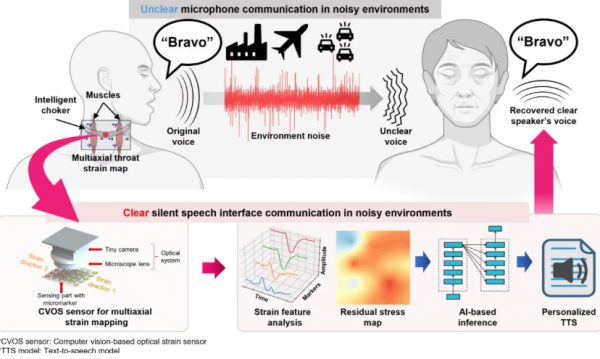
測試中,系統以北約音標字母表的 26 個字詞作訓練,例如 Alpha、Bravo、Charlie 等,辨識準確率達 85.8%。當 AI 辨認出用戶無聲讀出的字詞後,會無線傳送至伺服器,再由個人化文字轉語音模型合成聲音。研究人員稱,只需少於 10 分鐘錄音,系統便可模擬用戶的語調及聲音特徵。
研究亦顯示,裝置在約 90 分貝白噪音環境下仍可維持最高 33.75 分貝訊噪比,表現較商用肌電系統佳。團隊認為,技術有望協助喉切除患者、語言障礙人士,也可用於工業、救援、航空、航海及軍事等高噪音環境。
不過,現階段技術仍有明顯限制。系統只能辨識 26 個預設字詞,未能支援自由對話;若佩戴者步行或大幅擺動頭部,準確率可跌至 39.72%。研究團隊下一步將擴大測試人數、增加詞彙量,並改善身體活動時的穩定性。
相比英國劍橋大學早前同類頸帶研究曾錄得 95.25% 解碼準確率,POSTECH 方案的特點在於加入個人化 AI 聲音重建,令無聲溝通不只是「讀出文字」,而是更接近以本人聲音重新說話。
圖片:POSTECH
T10